代码概览¶
本文档概述了 Firefox 内部实现 Profiler 的代码,并详细介绍了一些棘手的问题,或指向更详细的文档和/或源代码。
本文档假定读者熟悉 Firefox 开发,包括 Mercurial (hg)、mach、moz.build 文件、Try、Phabricator 等。
本文档还假定读者了解 Firefox Profiler 对用户可见的部分,即:如何使用 Firefox Profiler,以及捕获分析时显示的分析内容。请参阅主网站 https://profiler.firefox.com 及其 文档。
对于“概览”,信息量可能看起来很大,但 Profiler 代码确实非常庞大,因此即使是高级别的概述也需要大量文字来解释!对于即时需求,可以在这里搜索一些术语并跟随线索。但对于长期维护者,最好浏览整个文档以掌握领域知识,并在深入代码之前返回获取更多详细信息。
WIP 注意:本文档在编写时应正确,但 Profiler 代码不断发展以响应 bug 或提供新的令人兴奋的功能,因此本文档的某些部分可能会过时!它仍然可以用作概述,但应通过查看实际代码来验证其正确性。如果您发现任何重大差异或损坏的链接,请通过 提交 bug 提供帮助。
术语¶
这是 Dev Tools 团队理解的一些常用术语的常见用法。但有时也可能出现错误用法,上下文是关键!
profiler (a): 用于启用代码分析的软件的通用名称。(“分析” 在维基百科上)
Profiler (the): Firefox 内部 Profiler 代码的所有部分。
Base Profiler (the): Profiler 的一部分,位于 mozglue/baseprofiler 中,可从任何地方使用,但功能有限。
Gecko Profiler (the): Profiler 的一部分,位于 tools/profiler 中,只能从 XUL 库中的其他代码中使用。
Profilers (the): Base Profiler 和 Gecko Profiler。
分析会话:Profiler 运行并收集数据的时间段。
profile (a): 分析会话的输出,可以是文件,也可以是 https://profiler.firefox.com 上共享的可视化分析。
Profiler 后端 (the): Firefox 内部 Profiler 代码的另一个名称,用于将其与…区分开来。
Profiler 前端 (the): 网站 https://profiler.firefox.com,用于显示后端捕获的分析。
Firefox Profiler (the): 由后端和前端组成的完整套件。
指导原则¶
在处理 Profiler 时,请牢记以下一些指导原则
降低 CPU 和内存的分析开销。为了让 Profiler 提供最佳价值,它应该尽量避免干扰并尽可能少地消耗资源(时间和内存),以免过多地影响实际的 Firefox 代码。
尽可能将公共数据结构和代码放在 Base Profiler 中。
WIP 注意:重复数据删除正在缓慢进行,请参阅 元 bug 1557566。本文档重点关注 Profiler 后端,主要是 Gecko Profiler(因为这里大部分代码都位于此处,Base Profiler 主要是一个子集,最初只是 Gecko Profiler 的精简版本);因此,除非另有说明,否则下面的描述都是关于 Gecko Profiler 的,但请注意,Base Profiler 中也可能存在一些等效的代码。
在可能的情况下使用适当的编程语言特性,以减少我们代码和用户使用代码时的编码错误。在 C++ 中,可以通过为给定用法使用特定的类/结构类型来避免误用(例如,表示进程的通用整数可能被错误地传递给期望线程的函数;我们为此提供了特定的类型,更多内容请参见下文)。
遵循 编码风格。
在可能的情况下,为添加或修改的代码编写测试(如果不存在),但这在某些情况下可能太困难了,请使用良好的判断力,至少手动测试。
生命周期¶
以下是 Base 或 Gecko Profiler 作为 Firefox 运行一部分的生命周期的高级视图。以下部分将详细介绍。
Profiler 初始化,准备一些公共数据。
线程在启动和停止时自行注销/注册。
在每个用户/测试控制的分析会话期间
Profiler 启动,准备存储分析数据的结构。
来自单独线程的周期性采样,以用户选择的频率(通常每 1-2 毫秒一次)进行,并记录 Firefox 正在执行的操作的快照
CPU 采样,测量每个线程实际在 CPU 上运行所花费的时间。
堆栈采样,捕获程序在此时间点所在的任何叶函数的函数调用堆栈,直到最顶层的调用者(即,至少是
main()函数,或者其任何调用者)。请注意,与大多数外部 Profiler 不同,Firefox Profiler 后端能够获取比仅原生函数调用(从 C++ 或 Rust 编译)更有用的信息Firefox 开发人员沿堆栈添加的标签,通常用于识别执行“有趣”操作(如布局、文件 I/O 等)的代码区域。
JavaScript 函数调用,包括应用的优化级别。
Java 函数调用。
在任何时候,标记都可以记录正在发生的事情的更多具体细节,例如:用户操作、页面渲染步骤、垃圾回收等。
可选的 Profiler 暂停,它会停止大多数记录,通常在会话结束附近,以便在此点之后不再记录任何数据。
分析 JSON 输出,由所有记录的分析数据生成。
Profiler 停止,拆除分析会话对象。
Profiler 关闭。
请注意,Base Profiler 可以更早启动,然后收集到的数据以及周期性采样的责任将转移到 Gecko Profiler
(Firefox 启动)
Base Profiler 初始化
Base Profiler 启动
(Firefox 加载 libxul 库并初始化 XPCOM)
Gecko Profiler 初始化
Gecko Profiler 启动
从 Base 到 Gecko 的移交
Base Profiler 停止
(分析会话主体)
JSON 生成
Gecko Profiler 停止
Gecko Profiler 关闭
(Firefox 结束 XPCOM)
Base Profiler 关闭
(Firefox 退出)
添加数据的 Base Profiler 函数(主要是标记和标签)可以从任何地方调用,并将由任一 Profiler 记录。Gecko Profiler 中的相应函数只能从其他 libxul 代码中调用,并且只能由 Gecko Profiler 记录。
如果可以访问,则应尽可能优先使用 Gecko Profiler 函数,因为它们可能提供扩展功能(例如,标记中更好的堆栈和 JS)。否则,回退到 Base Profiler 函数。
目录¶
非 Profiler 支持代码
mfbt - 主要替换 C++ std 库的功能。
-
PlatformMutex.h - 互斥锁基类。
StackWalk.h - 堆栈遍历函数。
TimeStamp.h - 时间戳和时间持续时间。
Profiler 后端
mozglue/baseprofiler - Base Profiler 代码,可在 Firefox 的任何地方使用。因为它位于 mozglue 中,所以在开始时就会加载,因此可以在非常早的时候启动 Profiler,甚至在 Firefox 加载其庞大且沉重的“xul”库之前。
baseprofiler 的公共部分 - 公共头文件,可以从任何地方包含。
baseprofiler 的核心部分 - 主要实现代码。
baseprofiler 的 lul 部分 - Linux 的特殊堆栈遍历代码。
../tests/TestBaseProfiler.cpp - 单元测试。
tools/profiler - Gecko Profiler 代码,只能从 xul 库中使用。该库在 Firefox 启动后不久加载,因此 Gecko Profiler 无法分析应用程序的早期阶段,Base Profiler 处理此阶段,并在后者启动时将其收集的数据传递给 Gecko Profiler。
devtools/client/performance-new,devtools/shared/performance-new - about:profiling 和开发者工具面板功能的中介代码。
js,从 js/src/vm/GeckoProfiler.h 开始 - JavaScript 引擎支持,主要用于捕获 JS 栈。
toolkit/components/extensions/schemas/geckoProfiler.json - 当 Profiler 功能发生变化时需要更新的文件。
Profiler 前端
不在本文档的范围内,但其代码和错误库可以在以下位置找到:https://github.com/firefox-devtools/profiler。有时需要同时在前端的后端进行工作,尤其是在修改后端的 JSON 输出格式时。
头文件¶
最核心的公共头文件是 GeckoProfiler.h,从中可以找到几乎所有其他内容,它可以作为探索的良好起点。它包含其他头文件,这些头文件共同包含重要的顶级宏和函数。
待办事项:GeckoProfiler.h 曾经是包含所有内容的头文件!为了更好地分离功能区域,并希望减少编译时间,它的一部分已被拆分为更小的头文件,这项工作将继续进行,请参阅 bug 1681416。
MOZ_GECKO_PROFILER 和宏¶
Mozilla 正式支持在 一级平台 上使用 Profiler:Windows、macOS、Linux 和 Android。还有一些代码在二级/三级平台上运行(例如,用于 FreeBSD),但 Mozilla 团队没有义务维护它;我们会尽量保持其运行,一些外部贡献者也在关注它,并在出现问题时提供补丁。
为了减少对不受支持平台的负担,许多 Profiler 代码仅在定义了 MOZ_GECKO_PROFILER 时编译。这意味着某些公共函数可能并不总是声明或实现,并且应该用诸如 #ifdef MOZ_GECKO_PROFILER 之类的保护语句包围。
一些常用的函数在非 MOZ_GECKO_PROFILER 的情况下提供了空定义,因此这些函数可以在任何地方调用而无需保护语句。
其他函数有相关的宏,这些宏始终可以使用,并在不受支持的平台上解析为空。例如,PROFILER_REGISTER_THREAD 在支持的情况下调用 profiler_register_thread,否则什么也不做。
待办事项:正在努力最终去除 MOZ_GECKO_PROFILER 及其相关的宏,请参阅 bug 1635350。
RAII “自动”宏和类¶
许多函数旨在成对调用,通常用于启动然后结束某个操作。为了方便使用,并确保始终一起调用这两个函数,它们通常有一个关联的类和/或宏,这些类和/或宏只能调用一次。这种使用对象的析构函数来确保某些操作最终始终发生的方式,在 C++ 中称为 RAII,使用常见的“auto”前缀。
例如:在 MOZ_GECKO_PROFILER 构建中,AUTO_PROFILER_INIT 实例化一个 AutoProfilerInit 对象,该对象在构造时调用 profiler_init,在销毁时调用 profiler_shutdown。
平台抽象¶
本节描述了 Profiler 中使用的某些平台抽象。(其他平台抽象将在使用时进行描述。)
进程和线程 ID¶
Profiler 后端通常使用进程和线程 ID(也称为“pid”和“tid”),它们通常只是一个数字。为了提高代码正确性,并隐藏特定的平台细节,它们被封装在不透明类型 BaseProfilerProcessId 和 BaseProfilerThreadId 中。应尽可能使用这些类型。在与其他代码交互时,可以使用成员函数 FromNumber 和 ToNumber 进行转换。
要查找当前进程或线程 ID,请使用 profiler_current_process_id 或 profiler_current_thread_id。
主线程 ID 可通过 profiler_main_thread_id 获取(假设在应用程序启动时调用了 profiler_init_main_thread_id - 这在独立测试程序中尤其重要)。profiler_is_main_thread 是一种快速判断当前线程是否为主线程的方法。
锁定¶
PlatformMutex.h 中的锁定原语不应按原样使用,而应通过用户可访问的实现来使用。对于 Profiler,它位于 BaseProfilerDetail.h 中。
除了通常的 Lock、TryLock 和 Unlock 函数外,BaseProfilerMutex 对象还有一个名称(在调试时可能很有用),它们记录了锁定它们的线程(可以知道互斥量是否在当前线程上锁定),并且在 DEBUG 构建中,有一些断言验证互斥量没有被错误地递归使用,以验证不同 Profiler 互斥量的正确顺序,以及在销毁之前是否已解锁。
最好在 C++ 块作用域内或作为类成员使用 BaseProfilerAutoLock 锁定互斥量。
一些类提供了是否使用互斥量的选项(以便单线程代码可以更有效地绕过锁定操作),对于这些类,我们有 BaseProfilerMaybeMutex 和 BaseProfilerMaybeAutoLock。
还有一种特殊的共享锁类型(也称为 RWLock,请参阅 维基百科上的 RWLock),它可以在多个线程中锁定(通过 LockShared 或优选的 BaseProfilerAutoLockShared),或者排他性锁定,阻止任何其他锁定(通过 LockExclusive 或优选的 BaseProfilerAutoLockExclusive)。
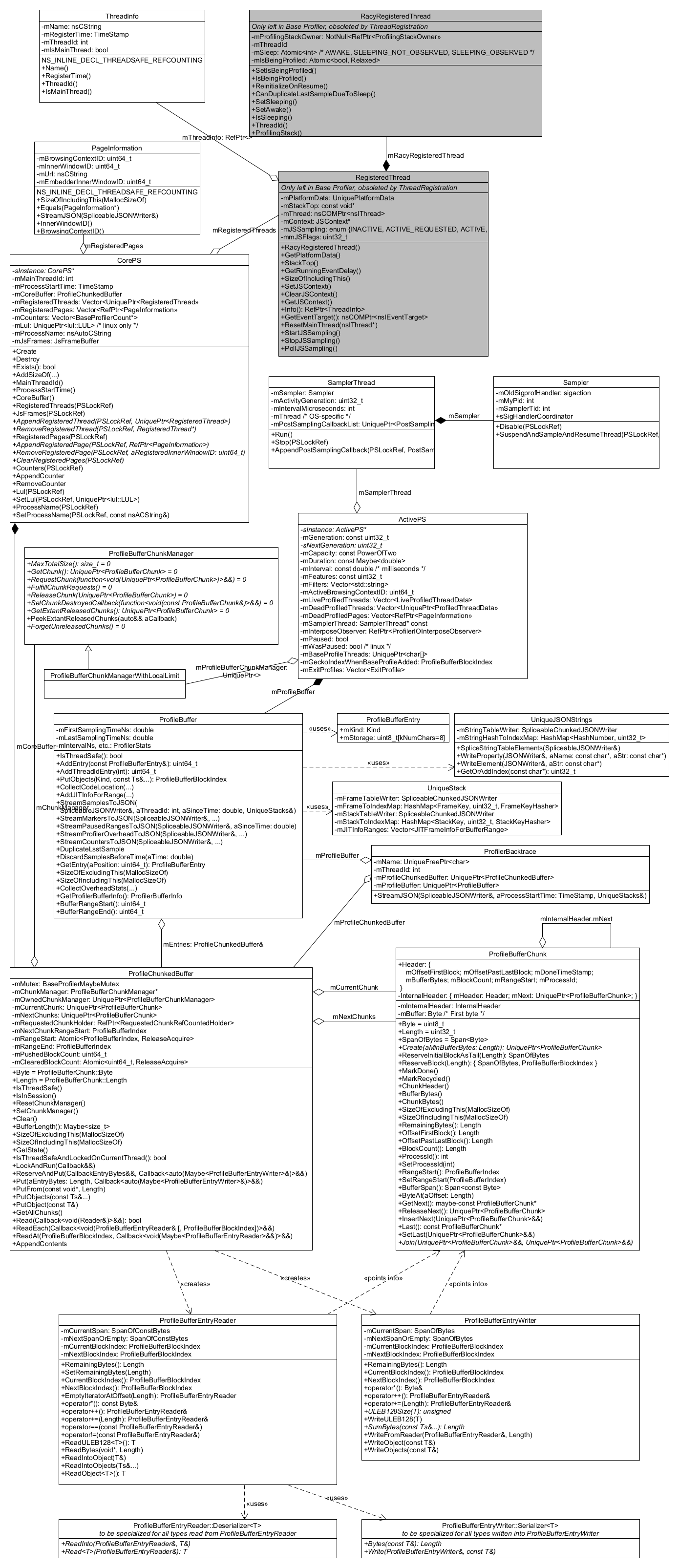
主要 Profiler 类¶
显示最重要的 Profiler 类的图表,请参阅以下各节中的详细信息
(如上所述,在 Gecko Profiler 中,“RegisteredThread”类现在已过时,请参阅下面的“线程注册”部分以获取更新的图表和描述。)
Profiler 初始化¶
profiler_init 和 baseprofiler::profiler_init 必须从主线程调用,用于准备 Profiler 的重要方面,包括
确保记录主线程 ID。
处理
MOZ_PROFILER_HELP=1 ./mach run以显示命令行帮助。创建
CorePS实例 - 更多详细信息请参见下文。注册主线程。
初始化一些特定于平台的代码。
处理其他用于立即启动 Profiler 的环境变量,以及在其他 env-vars 中提供的可选设置。
CorePS¶
CorePS 类 只有一个实例,应该在 Firefox 应用程序的整个生命周期内存在,并包含即使 Profiler 未运行也可能需要的重要信息。
它包括
指向其单个实例的静态指针。
进程启动时间。
特定于 JavaScript 的数据结构。
已注册的 PageInformations 列表,用于跟踪此进程处理的选项卡。
已注册的 BaseProfilerCounts 列表,用于记录进程内存使用情况等内容。
进程名称,以及可选的此进程处理的“eTLD+1”(大致为子域名)。
仅在 Base Profiler 中,RegisteredThreads 列表。待办事项:此存储已在 Gecko Profiler 中进行了重新设计(更多信息请参见下文),并且在实践中,Base Profiler 仅注册主线程。这最终应该作为重复数据删除工作的一部分消失(bug 1557566)。
线程注册¶
线程需要自行注册才能被完全分析。本节介绍记录已注册线程列表及其数据的的主要数据结构。
待办事项:有一些工作正在进行,以添加对未注册线程的有限分析,希望可以添加越来越多的功能,最终使用相同的数据结构。
显示相关类的图表,请参阅以下小节中的详细信息
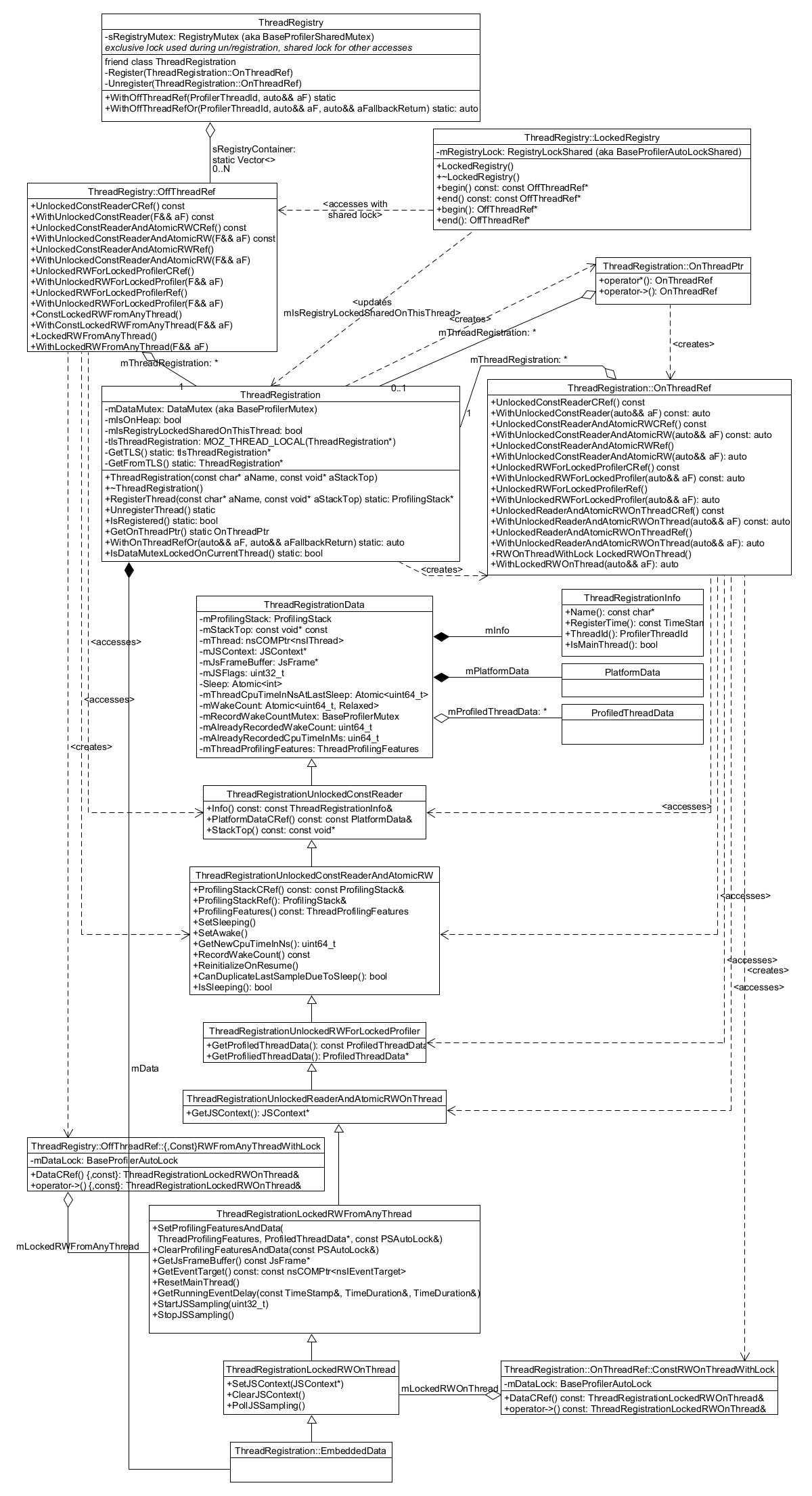
ProfilerThreadRegistry¶
静态 ProfilerThreadRegistry 对象 包含一个 OffThreadRef 对象列表。
每个 OffThreadRef 都指向一个 ProfilerThreadRegistration,并限制对线程数据的安全子集的访问,并在必要时强制互斥量锁定(更多信息请参见下面的 ProfilerThreadRegistrationData)。
ProfilerThreadRegistration¶
ProfilerThreadRegistration 对象 包含与其线程相关的大量信息,以帮助对其进行分析。
可以通过一个 OnThreadRef 对象从线程本身访问此数据,该对象指向 ThreadRegistration,并限制对线程数据的安全子集的访问,并在必要时强制互斥量锁定(更多信息请参见下面的 ProfilerThreadRegistrationData)。
ThreadRegistrationData 和访问器¶
ProfilerThreadRegistrationData.h 头文件 包含一个封装所有线程相关数据的类层次结构。
ThreadRegistrationData 包含所有实际的数据成员,包括
一些长生命周期的 ThreadRegistrationInfo,包含线程名称、注册时间、线程 ID 以及是否是主线程。
一个
ProfilingStack,用于收集开发者提供的伪帧和 JS 帧。一些平台特定的
PlatformData(通常需要实际记录该线程的性能分析测量数据)。指向栈顶的指针。
指向线程
nsIThread的共享指针。指向
JSContext的指针。一个可选的预分配
JsFrame缓冲区,用于堆栈采样期间。一些 JS 标志。
与休眠相关的数据(避免在已知线程空闲时进行代价高昂的采样)。
当前的
ThreadProfilingFeatures,用于了解要记录哪种数据。在进行性能分析时,指向一个
ProfiledThreadData的指针,其中包含性能分析期间和之后需要的一些更多数据。
如它们各自的代码注释中所述,每个数据成员都应该以特定的方式访问,例如,JSContext 应该“仅从线程写入,从线程和挂起线程读取”。为了强制执行这些规则,数据成员只能通过某些类访问,而这些类本身只能在正确的条件下实例化。
访问器类从基类到派生类依次为:
ThreadRegistrationData,本身不是访问器,但它是包含所有protected数据的基类。ThreadRegistrationUnlockedConstReader,提供对以下内容的未加锁const访问:ThreadRegistrationInfo、PlatformData和栈顶。
ThreadRegistrationUnlockedConstReaderAndAtomicRW,提供对原子数据成员的未加锁访问:ProfilingStack、与休眠相关的数据、ThreadProfilingFeatures。ThreadRegistrationUnlockedRWForLockedProfiler,提供受性能分析器主锁保护的访问,但不需要ThreadRegistration锁,用于访问ProfiledThreadData。ThreadRegistrationUnlockedReaderAndAtomicRWOnThread,提供未加锁的可变访问,但仅限于线程本身,用于访问JSContext。ThreadRegistrationLockedRWFromAnyThread,提供来自任何线程对互斥锁保护数据的加锁访问:ThreadProfilingFeatures、JsFrame、nsIThread和 JS 标志。ThreadRegistrationLockedRWOnThread,提供加锁访问,但仅限于线程本身,用于访问JSContext和与 JS 标志相关的操作。ThreadRegistration::EmbeddedData,包含以上所有内容,并作为每个ThreadRegistration中的数据成员存储。
概括地说,如果某些代码需要线程上的某些数据,它可以使用 ThreadRegistration 函数请求访问(具有所需的权限,例如互斥锁)。要访问有关其他线程的数据,请改用 ThreadRegistry 中的类似函数。您可以在 ProfilerThreadState.h 中函数的实现中找到一些示例(请参阅下一节)。
ProfilerThreadState.h 函数¶
ProfilerThreadState.h 头文件提供了一些与线程相关的有用函数,包括:
profiler_is_active_and_thread_is_registeredprofiler_thread_is_being_profiled(针对当前线程或其他线程,以及针对给定的功能集)profiler_thread_is_sleeping
性能分析器启动¶
有多种方法可以启动性能分析器,可以通过命令行环境变量,以及以 C++ 和 JS 方式进行编程启动。
主要的公共 C++ 函数是 profiler_start。它接收所有功能规范,并返回一个 Promise,当性能分析器在所有进程中完全启动时,该 Promise 会被解析(多进程性能分析将在本文档后面介绍,目前重点关注每个进程运行其性能分析器实例)。它首先根据需要调用 profiler_init,如果性能分析器已经在运行,则还调用 profiler_stop。
主要实现可以从多个源调用,是 locked_profiler_start。它执行许多操作以启动性能分析会话,包括:
记录会话开始时间。
预分配一些工作缓冲区,用于捕获主线程上标记的堆栈。
仅在 Gecko 性能分析器中:如果基础性能分析器正在运行,则获取迄今为止收集的数据的所有权,并停止基础性能分析器(我们不希望两者同时尝试收集相同的数据!)
创建 ActivePS,它跟踪大部分性能分析会话信息,更多信息请参见下文。
对于在
ThreadRegistry中找到的每个已注册线程,检查它是否是要分析的线程之一,如果是,则将相应的数据设置到相应的ThreadRegistrationData中(包括通知 JS 引擎开始记录性能分析数据)。在 Android 上,启动 Java 采样器。
如果要分析本地分配,则设置相应的钩子。
如果请求,则启动音频回调跟踪。
设置公共共享的“活动”状态,许多函数都使用它来快速评估是否实际记录性能分析数据。
ActivePS¶
ActivePS 类 每次只有一个实例,应该在性能分析会话期间存在。
它包括
会话开始时间。
一种跟踪“代”的方法(如果在下一个 ActivePS 启动时旧的 ActivePS 仍然存在,以便正在进行中的数据转到正确的位置)。
请求的功能:缓冲区容量、周期性采样间隔、功能集、要分析的线程列表,可选:要分析的特定标签。
性能分析数据存储缓冲区及其块管理器(有关详细信息,请参阅下面的“存储”部分)。
有关活动和已死性能分析线程的更多数据。
每个进程的 CPU 使用率和功耗的可选计数器。
指向
SamplerThread对象的指针(有关详细信息,请参阅下面的“周期性采样”部分)。
存储¶
在会话期间,性能分析数据被序列化到一个缓冲区中,该缓冲区由“块”组成,每个块包含“块”,块具有大小和“条目”数据。
在性能分析会话期间,有一个主性能分析缓冲区,它可能由基础性能分析器启动,然后在后者启动时移交给 Gecko 性能分析器。
缓冲区被分成大小相等的块,这些块在需要之前分配。当数据达到用户设置的限制时,最旧的块会被回收。这意味着对于足够长的性能分析会话,只会保留最近的数据(可以容纳在限制范围内)。
每个块存储一系列可变长度的块。块本身只知道第一个完整块的起始位置,以及最后一个块的结束位置,这是下一个块将被预留的位置。
要将条目添加到缓冲区,将预留一个块,首先写入大小(以便读取器可以找到下一个块的开头),然后写入条目字节。
以下部分提供了更多技术细节。
leb128iterator.h¶
此实用程序头文件 包含一些用于读取和写入无符号“LEB128”数字的函数(维基百科上的 LEB128)。
它们是序列化通常很小的数字的有效方法,例如,最多 127 的数字只需要一个字节,两个字节最多 16,383,依此类推。
ProfileBufferBlockIndex¶
ProfileBufferBlockIndex 对象 封装了一个已知是块有效起点的块索引。当预留块时或当受信任的代码计算块在块中的起点时,会创建它。
当在块内工作时,使用更通用的 ProfileBufferIndex 类型。
ProfileBufferChunk¶
ProfileBufferChunk 是一个可变大小的对象。它包含:
一个公共的可复制头,本身包含:
第一个完整块的本地偏移量(块可能以在上一个块末尾开始的块的末尾开始)。在第一个块中的该偏移量是读取缓冲区中所有数据的自然起点。
最后一个预留块之后的本地偏移量。这是下一个块应该被预留的位置,除非它指向该块大小的末尾。
首次使用该块的时间戳。
该块变满的时间戳。
可以存储在此块中的字节数。
预留块的数量。
此块开始处的全局索引。
写入此块的进程 ID。
指向下一个块的拥有唯一指针。对于链中的最后一个块,它可能为 null。
在
DEBUG版本中,一个状态变量,用于确保块经过一系列已知的状态(例如,已创建,然后正在使用,然后已完成,依此类推)。请参阅 成员变量定义位置 的序列图。实际的缓冲区数据。
因为 ProfileBufferChunk 是可变大小的,所以它必须通过其静态 Create 函数创建,该函数负责以正确的对齐方式分配正确的字节数。
块管理器¶
ProfilerBufferChunkManager¶
ProfileBufferChunkManager 抽象类 定义了管理块的类的接口。
具体实现负责:* 为其用户创建块,并提供一种机制在实际需要之前预分配块。* 当块“释放”时(通常是当块已满时)收回并拥有块。* 自动销毁或回收最旧的已释放块。* 对现有的已释放块提供临时访问。
ProfileBufferChunkManagerSingle¶
ProfileBufferChunkManagerSingle 对象 管理单个块。
该块始终相同,它永远不会被销毁。用户可以使用它并可以选择释放它。然后可以重置管理器,并且该块将再次可用。
请求第二个块将始终失败。
此管理器是短暂的且不是线程安全的。当需要捕获一些有限的数据而不阻塞全局性能分析缓冲区时,它非常有用,通常是一个堆栈样本。然后可以提取这些数据并快速添加到全局缓冲区。
ProfileBufferChunkManagerWithLocalLimit¶
ProfileBufferChunkManagerWithLocalLimit 对象 完全实现了 ProfileBufferChunkManager 接口,管理多个块,并确保它们的总组合大小保持在给定限制之下。这是性能分析会话期间使用的主要块管理器。
注意:它还实现了 ProfileBufferControlledChunkManager 接口,这将在后面的“多进程性能分析”部分解释。
它是线程安全的,并且性能分析器共享一个实例。
ProfileChunkedBuffer¶
ProfileChunkedBuffer 对象 使用 ProfilerBufferChunkManager 存储数据,并处理性能分析器想要在缓冲区块中作为条目读取/写入的不同 C++ 数据类型。
其主要功能是 ReserveAndPut
它接收一个可调用对象(如 lambda),该对象应返回要存储的条目的大小,这可能是为了避免代价高昂的操作仅仅是为了计算大小,而性能分析器可能没有运行。
它尝试在其块中预留空间,必要时请求新块。
然后,它使用 ProfileBufferEntryWriter 调用提供的可调用对象,它提供了一系列函数来帮助序列化 C++ 对象。反序列化/序列化函数可以在 ProfileBufferEntryWriter::Serializer 和 ProfileBufferEntryReader::Deserializer 的专门化中找到。
更多“put”函数使用 ReserveAndPut 更轻松地序列化内存块或 C++ 对象。
ProfileChunkedBuffer 可选地是线程安全的,使用 BaseProfilerMaybeMutex。
WIP 注意:使用互斥锁使得此存储对于分析某些实时(如音频处理)来说过于嘈杂。Bug 1697953 将考虑改为使用原子变量。另一种方法是为每个需要它的实时线程使用完全独立的非线程安全缓冲区(请参阅 bug 1754889)。
ProfileBuffer¶
ProfileBuffer 对象 使用 ProfileChunkedBuffer 存储数据,并处理性能分析器想要读取/写入的不同类型的条目。
每个条目都以一个标识类型的标签开头。这些类型可以在ProfileBufferEntryKinds.h中找到。
有一些“传统”类型,它们是小的固定长度条目,例如:类别、标签、帧信息、计数器等。这些可以存储在ProfileBufferEntry 对象中。
还有一些“现代”类型,它们具有可变大小,例如:标记、CPU 运行时间、完整堆栈等。这些由可以直接访问底层ProfileChunkedBuffer的代码更直接地处理。
ProfileChunkedBuffer的另一个主要职责是读取所有这些数据,有时在分析期间(例如,复制堆栈),但主要是在会话结束时生成输出 JSON 配置文件时。
周期性采样¶
也许 Profiler 最重要的工作是采样多个运行线程的堆栈,以帮助开发人员了解在 Firefox 上执行某些操作时哪些函数被大量使用。
这是通过一个特殊的线程实现的,该线程定期启动并捕获所有这些数据。
SamplerThread¶
SamplerThread 对象管理采样期间所需的信息。它在分析器启动时创建,并存储在ActivePS内部,有关详细信息,请参见上文。
它包括
一个
Sampler对象,包含特定于平台的细节,这些细节在单独的文件中实现,例如 platform-win32.cpp 等。与其所属的
ActivePS相同的生成索引。请求的样本之间的时间间隔。
采样发生线程的句柄,其主要功能是Run() 函数。
在下次采样后要调用的回调列表。测试可以使用这些回调来等待采样实际发生。
未注册线程的间谍数据,以及另一个线程的可选句柄,该线程负责处理未注册线程的“间谍”(在平台上,该操作在采样线程上直接运行成本过高)。
Run() 函数负责执行周期性采样工作:(以下部分将详细介绍)
检索采样参数。
在堆栈上实例化一个
ProfileBuffer,以捕获来自其他线程的样本。循环直到
break。锁定主分析器互斥锁,并执行以下操作
检查是否应停止采样,并退出循环。
清理退出配置文件(这些是从即将退出的子进程发送的配置文件,并且只要它们与此进程自己的缓冲区范围重叠,就会保留)。
记录整个进程的 CPU 利用率。
记录功耗。
对每个注册的计数器进行采样,包括内存计数器。
对于每个要分析的已注册线程
记录 CPU 利用率。
如果线程被标记为“仍在休眠”,则记录“与之前相同”的样本,否则挂起线程并获取完整堆栈样本。
在某些线程上,记录事件延迟以计算(无)响应性。WIP 注意:此实现可能会更改。
记录分析开销持续时间。
解锁主分析器互斥锁。
调用已注册的采样后回调。
监视未注册的线程。
根据请求的采样间隔以及此循环花费的时间,计算下一个采样循环应何时开始,并使线程休眠适当的时间。目标是尽可能规律,但如果某些/所有循环花费的时间过长,则不要过于努力地赶上,因为系统可能已经处于压力之下。
返回循环顶部。
如果我们在这里,则表示我们在上面遇到了循环
break。调用已注册的采样后回调,让他们知道采样已停止。
CPU 利用率¶
CPU 利用率存储为自上次采样以来线程或进程在 CPU 上运行所花费的毫秒数。
实现依赖于平台,可以在GetThreadRunningTimesDiff 函数和GetProcessRunningTimesDiff 函数中找到。
功耗¶
2022 年添加了能量探针。
堆栈¶
堆栈是从程序入口点(通常是main()和上面的一些特定于操作系统的函数)到当前正在执行代码的函数的一系列调用。
原生帧¶
编译后的代码,来自 C++ 和 Rust 源代码。
标签帧¶
具有任意文本的伪帧,从任何语言添加,主要来自 C++。
JS、Wasm 帧¶
对应于 JavaScript 函数的帧。
Java 帧¶
由 JavaSampler 记录。
堆栈合并¶
上述类型的帧都以不同的方式捕获,并且在最终获取实际堆栈样本(Java 除外)时,它们将合并成一个堆栈。
所有帧在调用堆栈中都有一个关联的地址,因此可以通过根据此堆栈地址对它们进行排序来合并它们。有关实现细节,请参见MergeStacks。
计数器¶
计数器是一种特殊的探针,可以在分析期间持续更新,并且SamplerThread将在每个循环中对其值进行采样。
内存计数器¶
这是主计数器。在分析会话期间,内存管理器中的挂钩会跟踪每个分配/释放操作,因此在每次采样时,我们都知道执行了多少操作,以及与上次采样相比当前内存使用情况。
分析开销¶
SamplerThread记录其采样循环各个部分之间的时间戳,并将其记录为采样开销。这可能有助于确定分析器本身是否使用了过多的计算机资源,这可能会使配置文件产生偏差并给出错误的印象。
未注册线程分析¶
在某些间隔(不一定每个采样循环,具体取决于操作系统),分析器可能会尝试查找未注册的线程,并记录有关它们的一些信息。
WIP 注意:此功能是实验性的,数据以主线程上的标记的形式捕获。需要做更多工作才能将这些数据放入像常规注册线程一样的轨道中,并捕获更多数据,如堆栈样本和标记。
标记¶
标记是具有精确时间戳或时间范围的事件,它们具有名称、类别、选项(从几个选项中选择)以及可选的特定于标记类型的有效负载数据。
在描述实现之前,熟悉从 C++ 本地添加标记的方式很有用,因为这驱动着实现如何获取所有这些信息并最终将其输出到最终的 JSON 配置文件中。
从 C++ 添加标记¶
参见https://firefox-source-docs.mozilla.ac.cn/tools/profiler/markers-guide.html
实现¶
记录标记的主要函数是profiler_add_marker。它是一个可变参数模板函数,它采用不同的预期参数,首先检查是否应实际记录标记(分析器应正在运行,并且目标线程应已进行分析),然后调用更深层的实现函数AddMarkerToBuffer,并提供对主分析器缓冲区的引用。
AddMarkerToBuffer将标记类型作为对象,从函数参数列表中删除它,并使用标记类型作为显式模板参数,以及指向可以捕获堆栈的函数的指针(因为它在 Base 和 Gecko 分析器之间有所不同,特别是后者了解 JS)调用下一个函数。
从这里,我们进入BaseProfilerMarkersDetail.h的领域,它采用了一些繁重的模板技术,以便最有效地序列化给定的标记有效负载参数,以便在输出最终 JSON 时使它们可反序列化。在以前的实现中,对于每个新的标记类型,都需要一个从有效负载抽象类派生的新的 C++ 类,该类必须实现所有构造函数和虚函数以
创建有效负载对象。
将有效负载序列化到配置文件缓冲区中。
从配置文件缓冲区反序列化到新的有效负载对象。
将有效负载转换为最终输出 JSON。
现在,模板函数会自动处理所有给定函数调用参数的序列化(而不是首先将它们存储在某个地方),并准备一个反序列化函数,该函数将在堆栈上重新创建它们,并直接使用这些参数调用用户提供的 JSON 化函数。
从公共AddMarkerToBuffer开始,mozilla::base_profiler_markers_detail::AddMarkerToBuffer如果调用方未指定,则设置一些默认值:定位当前线程,使用当前时间。
然后,如果请求了堆栈捕获,则尝试以最有效的方式执行,如果可能,使用预分配的缓冲区。
WIP 注意:此潜在的分配应在时间关键线程中避免。主线程(因为它是最繁忙的线程)已经有一个缓冲区,但可以有更多预分配的线程,用于需要它的特定实时线程,或者从预分配缓冲区的池中选择。参见bug 1578792。
从那里,AddMarkerWithOptionalStackToBuffer以特殊方式处理NoPayload标记(通常使用PROFILER_MARKER_UNTYPED添加),主要目的是避免与处理有效负载相关的额外工作。否则,它将继续执行以下函数。
MarkerTypeSerialization<MarkerType>::Serialize检索与标记类型关联的反序列化标记。如果这是第一次使用此标记类型,则Streaming::TagForMarkerTypeFunctions将其添加到全局列表中(该列表存储反序列化期间使用的一些函数指针)。
然后,主要序列化发生在StreamFunctionTypeHelper<decltype(MarkerType::StreamJSONMarkerData)>::Serialize中。分解这个冗长的模板
MarkerType::StreamJSONMarkerData是最终将生成最终 JSON 的用户提供的函数,但此处仅用于了解它期望的参数类型。StreamFunctionTypeHelper获取该函数原型,并可以通过专门化`R(SpliceableJSONWriter&, As...)来提取其参数,现在As...是与函数参数匹配的参数包。请注意,
Serialize还采用参数包,其中包含传递给顶部AddBufferToMarker调用的所有引用参数。这两个包应该匹配,至少给定的参数应该可以转换为目标包参数类型。该专门化的
Serialize函数调用缓冲区的PutObjects可变参数函数来写入所有标记数据,即必须位于每个缓冲区条目开头的条目类型,在本例中为ProfileBufferEntryKind::Marker。
通用标记数据(选项优先、名称、类别、反序列化标记)。
然后是所有特定于标记类型的参数。请注意,C++ 类型是从反序列化函数中提取的,因此我们知道此处序列化的任何内容都可以稍后使用相同的类型进行反序列化。
反序列化方面在后面的“标记的 JSON 输出”部分进行了描述。
从 Rust 添加标记¶
参见https://firefox-source-docs.mozilla.ac.cn/tools/profiler/instrumenting-rust.html#adding-markers
从 JS 添加标记¶
参见https://firefox-source-docs.mozilla.ac.cn/tools/profiler/instrumenting-javascript.html
从 Java 添加标记¶
分析日志¶
在分析会话期间,可以使用ProfilingLog::Access记录一些与分析器相关的事件。
生成的 JSON 对象在进程的 JSON 生成过程接近尾声时添加,位于名为“profilingLog”的顶级属性中。此对象是自由格式的,不打算显示,甚至大多数人也不会读取。但它可能包含供高级用户查看的有趣信息,或者可以作为新功能的早期临时原型开发场所。
有关与后期事件相关的另一个日志,请参阅“profileGatheringLog”。
待完成说明:此功能是在撰写本文档之前不久引入的,因此目前它几乎没有任何作用。
性能分析捕获¶
通常,在性能分析会话结束时,会“捕获”性能分析数据,并将其保存到磁盘或发送到前端 https://profiler.firefox.com 进行分析。本节介绍如何将捕获的数据转换为 Gecko Profiler JSON 格式。
故障锁¶
故障锁接口 用于 JSON 生成过程中,以便捕获任何不可恢复的错误(例如内存不足),尽早退出进程,并将错误转发给调用方。
有两个主要实现,后缀为“source”,因为它们是故障处理的唯一来源,作为 FailureLatch& 传递到整个代码中。
FailureLatchInfallibleSource 是一个“不可失败”的锁,这意味着它不期望出现任何故障。因此,如果确实发生了故障,程序将立即终止!(这是引入这些锁之前默认的行为。)
FailureLatchSource 是一个“可失败”的锁,它将记录发生的第一个故障,并“锁定”到故障状态。代码应定期检查此状态,并在可能时尽早返回。最终,此故障状态可能会公开给最终用户。
进度记录器,比例值¶
进度记录器对象 用于跟踪长时间操作的进度,在本例中为 JSON 生成过程。
为了匹配 JSON 生成代码的工作方式(作为 C++ 函数调用的树),每个函数中的 ProgressLogger 通常会在该函数内部本地记录从 0 到 100% 的进度。如果该函数调用子函数,则会为其提供一个子记录器,在调用函数中,子记录器设置为表示一个本地子范围(例如 20% 到 40%),但在被调用函数中,它看起来像自己的本地 ProgressLogger,从 0 到 100%。最顶层的 ProgressLogger 将最深层的本地进度值转换为相应的全局进度。
进度值记录在 ProportionValue 对象 中,这些对象有效地记录了没有精度损失的分数值。
当父进程等待子进程完成其工作时,此进度最为有用,以确保进度确实在发生,否则停止等待冻结的进程。有关详细信息,请参阅下面的“多进程性能分析”部分。
JSON 写入器¶
JSON 写入器对象 提供了一种简单的方法来创建 JSON 流(开始/结束集合,添加元素等),并回调到提供的 JSONWriteFunc 接口 以输出字符。
虽然这些类位于 Profiler 目录之外,但有时可能值得维护和/或修改它们以更好地满足 Profiler 的需求。但还有其他用户,因此请注意不要破坏其他内容!
可拼接 JSON 写入器和可拼接分块 JSON 写入器¶
由于 Profiler 处理大量数据(大型性能分析数据可能需要几十到数百兆字节!),因此一些专门的包装器添加了对这些大型 JSON 流的更好处理。
可拼接 JSON 写入器 是 JSONWriter 的子类,允许“拼接” JSON 字符串,即能够获取一个完整的格式良好的 JSON 字符串,并将其直接作为 JSON 对象插入到正在流式传输的目标 JSON 中。
它还提供了一些对 Profiler 非常有用的函数,例如:* 将时间戳转换为流中的 JSON 对象,注意保持纳秒精度,而不会在末尾出现不需要的零或九。* 添加多个空元素。* 添加唯一的字符串索引,并在必要时将该字符串添加到提供的唯一字符串列表中。(有关唯一字符串的更多信息,请参见下文。)
可拼接分块 JSON 写入器 是 SpliceableJSONWriter 的子类。其主要属性是它提供自己的写入器(ChunkedJSONWriteFunc),该写入器将流存储为一系列“块”(堆分配的缓冲区)。它以默认大小的块开始,并将传入的数据写入其中,并在以后根据需要分配更多块。这避免了始终调整大型缓冲区的大小。
它还提供与其父类相同的拼接功能,但在传入的 JSON 字符串来自另一个 SpliceableChunkedJSONWriter 的情况下,它能够窃取块并将它们添加到其列表中,从而避免昂贵的分配、复制和销毁操作。
唯一字符串¶
因为在性能分析数据中会重复很多字符串(例如,频繁的标记名称),所以这些字符串存储在单独的 JSON 字符串数组中,并使用此列表中的索引而不是完整字符串对象。
请注意,这些唯一字符串索引目前仅位于 JSON 树的特定位置,不能在任何接受字符串的位置使用。
UniqueJSONStrings 类 在 SpliceableChunkedJSONWriter 中存储此唯一字符串列表。给定一个字符串,如果第一次遇到该字符串,它会负责存储它,并将索引插入到目标 SpliceableJSONWriter 中。
JSON 生成¶
“Gecko 性能分析数据格式”可在 https://github.com/firefox-devtools/profiler/blob/main/docs-developer/gecko-profile-format.md 找到。
后端中的实现是 locked_profiler_stream_json_for_this_process。它主要按顺序输出每个 JSON 顶级 JSON 对象。有关每个对象如何输出,请参阅代码。请注意,对样本和标记有特殊处理,如下节所述。
进程流式传输上下文和线程流式传输上下文¶
在 JSON 性能分析数据中,样本和标记按线程和样本/标记分开。由于可能有几十到一百个线程,因此为这些组中的每一个读取完整的性能分析数据缓冲区一次的成本非常高。因此,缓冲区只读取一次,所有样本和标记在读取时都会被处理,并且它们的 JSON 输出会被发送到单独的 JSON 写入器。
进程流式传输上下文对象 包含促进此输出的所有信息,包括 线程流式传输上下文 列表,每个列表包含一个用于样本的 SpliceableChunkedJSONWriter 和一个用于此线程中标记的 SpliceableChunkedJSONWriter。
当从性能分析数据缓冲区读取条目时,样本和标记会通过其 ProfileBufferEntryKind 找到,并且作为反序列化任一类型的一部分(有关每个类型的更多信息,请参见下文),线程 ID 会被读取,并确定哪个 ThreadStreamingContext 将接收 JSON 输出。
在此过程结束时,所有 SpliceableChunkedJSONWriters 都会有效地拼接(主要是指针移动)到最终的 JSON 输出中。
样本的 JSON 输出¶
此工作在 ProfileBuffer::DoStreamSamplesAndMarkersToJSON 中完成。
从主 ProfileChunkedBuffer 中,访问每个条目,首先读取其 ProfileBufferEntryKind,对于样本,捕获的堆栈中的所有帧都会转换为相应的 JSON。
UniqueStacks 对象 用于对帧甚至子堆栈进行重复数据删除。
每个唯一的帧字符串都写入
SpliceableChunkedJSONWriter内部的 JSON 数组中,其索引是帧标识符。每个堆栈级别也进行了重复数据删除,并识别关联的帧字符串,并指向调用堆栈级别(即更靠近根目录)。
最后,存储堆栈顶部的标识符,以及时间戳(以及可能的一些其他信息)作为样本。
例如,如果我们收集了以下样本
A -> B -> C
A -> B
A -> B -> D
帧表将包含每个帧名称,例如:["A", "B", "C", "D"]。因此,包含“A”的帧的索引为 0,“B”的索引为 1,依此类推。
堆栈表将包含每个堆栈级别,例如:[[0, null], [1, 0], [2, 1], [3, 1]]。[0, null] 表示帧为 0 (“A”),并且它没有调用方,它是根帧。[1, 0] 表示帧为 1 (“B”),其调用方为堆栈 0,在本例中,它只是前一个堆栈。
因此,存储在线程数据中的三个样本将是:2、1、3(例如:“2”在堆栈表中指向帧 [2,1],其中包含“C”,然后从它们向下到“B”,然后到“A”)。
所有这些都包含重建所有完整堆栈样本所需的信息。
标记的 JSON 输出¶
这也发生在 ProfileBuffer::DoStreamSamplesAndMarkersToJSON 中。
当遇到 ProfileBufferEntryKind::Marker 时,DeserializeAfterKindAndStream 函数 读取 MarkerOptions(如上所述存储),其中包括线程 ID,用于识别要使用哪个 ThreadStreamingContext 的 SpliceableChunkedJSONWriter。
之后,输出通用标记数据(时间、类别等)。
然后,Streaming::DeserializerTag 识别此标记的类型。特殊情况 0(无有效负载)表示不会输出更多内容。
否则,如果存在有效负载,则会输出一些更常见的有效负载数据,特别是“内部窗口 ID”(用于将标记与特定 html 框架匹配)和堆栈。
待完成说明:其中一些将来可能会发生变化,请参阅 错误 1774326、错误 1774328 等。
对于 C++ 编写的有效负载,DeserializerTag 识别要使用的 MarkerDataDeserializer 函数。这是 BaseProfilerMarkersDetail.h 中大量模板代码的一部分,该函数定义为 MarkerTypeSerialization<MarkerType>::Deserialize,它输出标记类型名称,然后输出每个标记有效负载参数。后者是通过使用用户定义的 MarkerType::StreamJSONMarkerData 参数列表完成的,并递归地将每个参数从性能分析数据缓冲区反序列化到相应类型的栈上变量中,在最后,可以调用 MarkerType::StreamJSONMarkerData,其中包含所有这些参数,并且该函数会根据用户编程执行实际的 JSON 流式传输。
性能分析停止¶
请参阅“性能分析开始”并执行相反的操作!
对 SampleThread 对象有一些特殊处理,只是为了确保它在主性能分析互斥锁解锁后被删除,否则这可能导致死锁(因为它需要在能够检查指示采样循环和线程应结束的状态变量之前获取锁)。
性能分析关闭¶
请参阅“性能分析初始化”并执行相反的操作!
另一个操作是处理可选的 MOZ_PROFILER_SHUTDOWN 环境变量,以便在性能分析器正在运行时输出性能分析数据。
多进程性能分析¶
以上所有解释都集中在分析器在每个进程中所做的工作:启动、运行和收集样本、标记以及更多数据,输出 JSON 配置文件,以及停止。
但 Firefox 是一个多进程程序,因为 电解,也称为 e10s 引入了子进程来处理 Web 内容和扩展,尤其是在 Fission 强制即使是同一网页的部分内容也在单独的进程中运行之后,主要是为了增强安全性。从那时起,Firefox 可以生成许多进程,有时在访问繁忙的网站时会生成 10 到 20 个进程。
以下部分解释了如何对整个 Firefox 进行分析。
IPC(进程间通信)¶
参见 https://firefox-source-docs.mozilla.ac.cn/ipc/。
简单总结一下,一些消息传递函数式声明位于 PProfiler.ipdl 中,相应的 SendX 和 RecvX C++ 函数分别在 PProfilerParent.h 中生成,并在 PProfilerChild.h 中进行虚拟声明(供用户实现)。
在分析期间¶
退出配置文件¶
一个不在 PProfiler.ipdl 中的 IPC 消息是 ShutdownProfile,位于 PContent.ipdl 中。
它从 ContentChild::ShutdownInternal 调用,在子进程结束之前,如果分析器正在运行,则确保收集配置文件数据并将其发送到父进程,以便存储在其 ActivePS 中。
有关详细信息,请参阅 ActivePS::AddExitProfile。请注意,记录了“收集时的缓冲区位置”(实际上是全局配置文件缓冲区中存在的最大 ProfileBufferBlockIndex)。稍后,ClearExpiredExitProfiles 会查看缓冲区中仍然存在的最小 ProfileBufferBlockIndex(因为早期的块可能已被丢弃以限制内存使用),并丢弃之前记录的退出配置文件,因为它们的数据现在比父进程中存储的任何数据都旧。
配置文件缓冲区全局内存控制¶
每个进程都运行自己的分析器,每个分析器都有自己的配置文件分块缓冲区。为了使所有这些缓冲区的总体内存使用量保持在用户选择的限制范围内,进程协同工作,父进程负责监督。
显示相关类的图表,请参阅以下小节中的详细信息
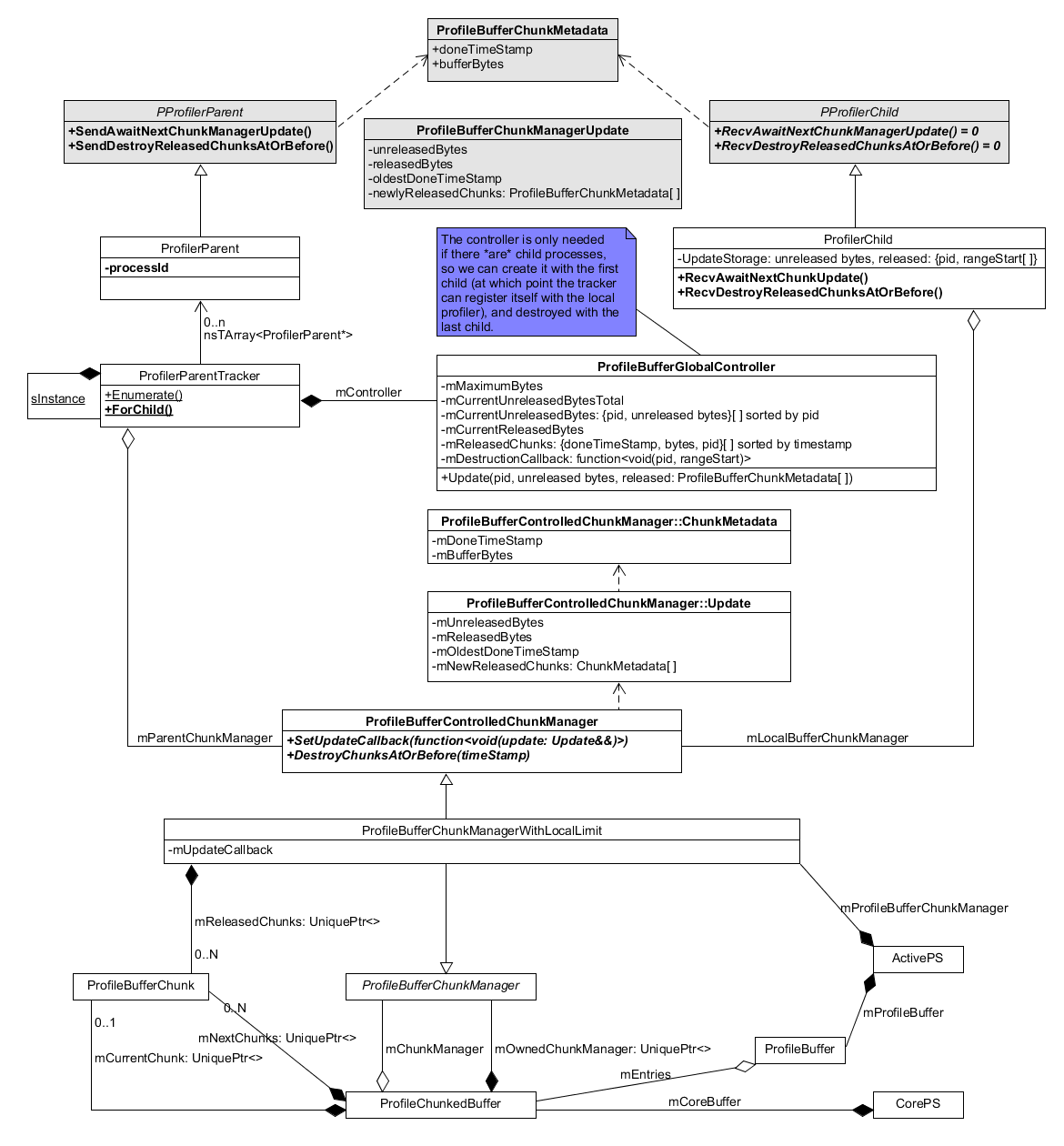
ProfileBufferControlledChunkManager¶
ProfileBufferControlledChunkManager 接口 允许控制器接收有关所有块更新的通知,并强制销毁/回收旧块。ProfileBufferChunkManagerWithLocalLimit 类实现了它。
更新对象 包含与块更改相关的所有信息:本地块管理器当前使用了多少内存,有多少内存已“释放”(因此可以销毁/回收),以及自上次更新以来释放的所有块的列表;它还具有一个特殊状态,表示子进程正在关闭,因此不会再有更新。可以将一个 Update “折叠”到前一个 Update 中,以创建等效于这两个单独 Update 的组合更新。
ProfilerChild 中的更新处理¶
当分析器在子进程中启动时,ProfilerChild 开始侦听更新。
这些更新将被存储并折叠到以前的更新中(如果有)。在某个时刻,将收到 AwaitNextChunkManagerUpdate 消息,并且可以将任何更新转发到父进程。本地更新将被清除,准备存储将来的更新。
ProfilerParent 中的更新处理¶
当分析器启动并且存在子进程时,ProfilerParent 的 ProfilerParentTracker 会创建 ProfileBufferGlobalController,后者开始侦听来自本地块管理器的更新。
ProfilerParentTracker 还负责跟踪子进程,并定期 向它们发送 AwaitNextChunkManagerUpdate 消息,子进程的 ProfilerChild 会使用更新来响应这些消息。更新可能指示子进程正在关闭,在这种情况下,跟踪器将停止跟踪它。
所有这些更新(来自本地块管理器和来自子进程自己的块管理器)都在 ProfileBufferGlobalController::HandleChunkManagerNonFinalUpdate 中进行处理。根据此更新流,可以计算所有进程中所有配置文件缓冲区使用的总内存,并跟踪所有已“释放”(即已满且可以销毁)的块。当总内存使用量达到用户选择的限制时,控制器可以查找最旧的块并将其销毁(对于父块,可以使用本地调用,或者通过向拥有它的子进程发送 DestroyReleasedChunksAtOrBefore 消息 来销毁)。
历史说明:在 Fission 之前,Profiler 习惯于在每个进程中保留一个固定大小的循环缓冲区,但由于 Fission 使进程数量变得无限,因此内存消耗增长过快,需要实现上述系统。但在代码或文档中可能仍然存在“循环缓冲区”的提及;这些已被分块缓冲区有效地取代,并由集中的块控制。
收集子进程配置文件¶
当需要捕获完整配置文件时,父进程执行其自己的 JSON 生成(如上所述),并向所有子进程发送 GatherProfile 消息,这将使它们生成自己的 JSON 配置文件并将其发送回父进程。
所有子进程配置文件,包括在分析期间收集的退出配置文件,都存储为具有属性名称“processes”的顶级数组的元素。
在收集阶段,当父进程等待子进程响应时,它会定期向尚未发送其配置文件的所有子进程发送 GetGatherProfileProgress 消息,并且父进程期望在短时间内收到响应。响应包含进度值。如果在某个时刻发送了两条消息,但任何地方都没有取得进度(要么没有响应,要么进度值没有改变),则父进程假设剩余的子进程可能无限期冻结,停止收集并认为 JSON 生成已完成。
在上述所有工作期间,都会记录事件(尤其是子进程问题),并在 JSON 配置文件的末尾添加,位于具有属性名称“profileGatheringLog”的顶级对象中。此对象是自由格式的,并非旨在显示,甚至大多数人都不需要阅读它。但它可能包含有关高级用户在配置文件收集阶段的有趣信息。